🎉 Accepted by ICCV 2025.
🌟 Downloaded 10,000+ times on Hugging Face after one month of release.
✨ Ranked Top 1 in the Hugging Face Dataset Trending List for the visual generation community (image-to-video, text-to-video, text-to-image, and image-to-image) on November 10, 2024.
🔥 Featured in Hugging Face Daily Papers on November 9, 2024.

TIP-I2V is the first dataset comprising over 1.70 million unique user-provided text and image prompts. Besides the prompts, TIP-I2V also includes videos generated by five state-of-the-art image-to-video models (Pika, Stable Video Diffusion, Open-Sora, I2VGen-XL, and CogVideoX-5B). The TIP-I2V contributes to the development of better and safer image-to-video models.
Abstract
Video generation models are revolutionizing content creation, with image-to-video models drawing increasing attention due to their enhanced controllability, visual consistency, and practical applications. However, despite their popularity, these models rely on user-provided text and image prompts, and there is currently no dedicated dataset for studying these prompts. In this paper, we introduce TIP-I2V, the first large-scale dataset of over 1.70 million unique user-provided Text and Image Prompts specifically for Image-to-Video generation. Additionally, we provide the corresponding generated videos from five state-of-the-art image-to-video models. We begin by outlining the time-consuming and costly process of curating this large-scale dataset. Next, we compare TIP-I2V to two popular prompt datasets, VidProM (text-to-video) and DiffusionDB (text-to-image), highlighting differences in both basic and semantic information. This dataset enables advancements in image-to-video research. For instance, to develop better models, researchers can use the prompts in TIP-I2V to analyze user preferences and evaluate the multi-dimensional performance of their trained models; and to enhance model safety, they may focus on addressing the misinformation issue caused by image-to-video models. The new research inspired by TIP-I2V and the differences with existing datasets emphasize the importance of a specialized image-to-video prompt dataset.
Datapoint

Statistics
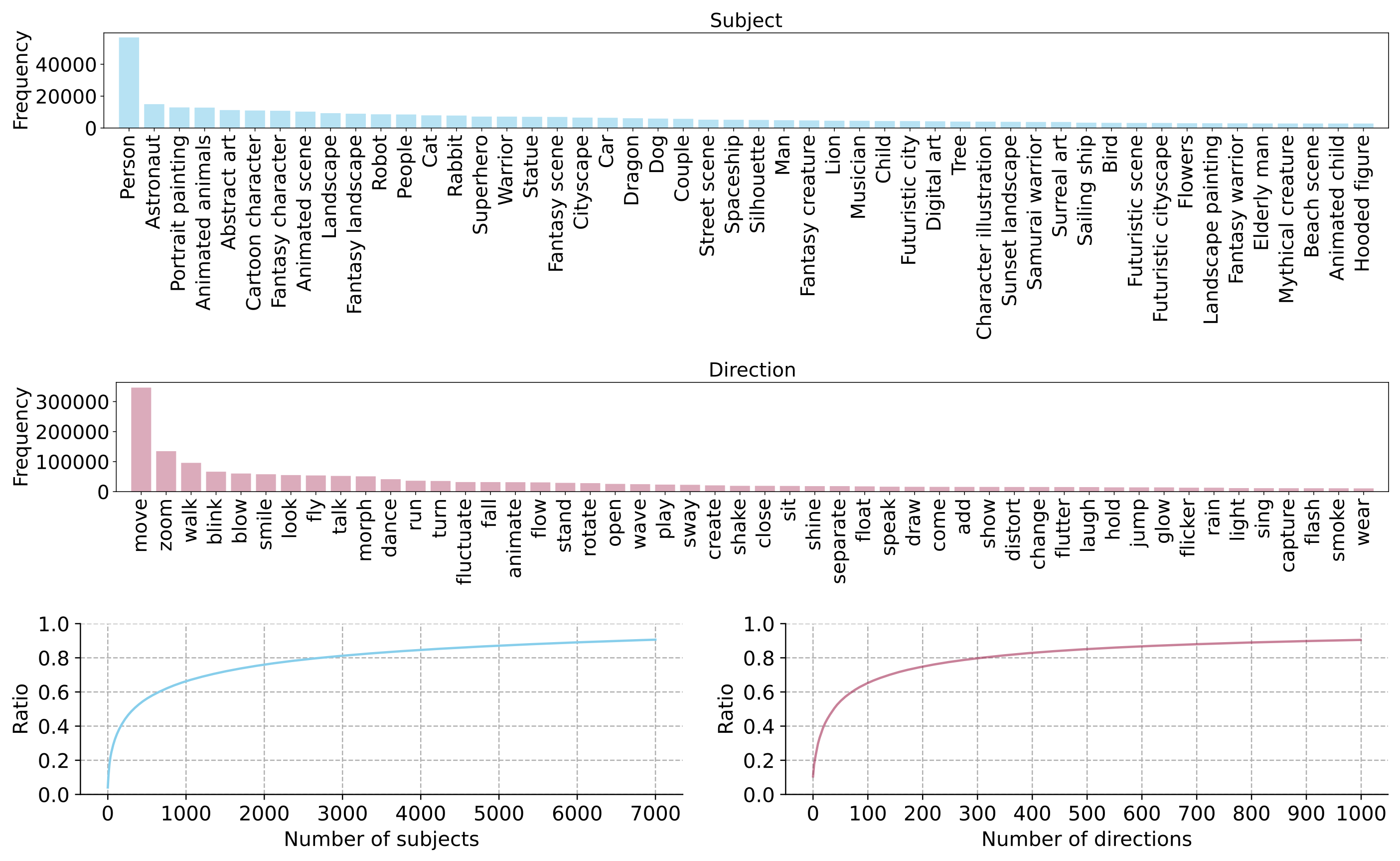
Examples


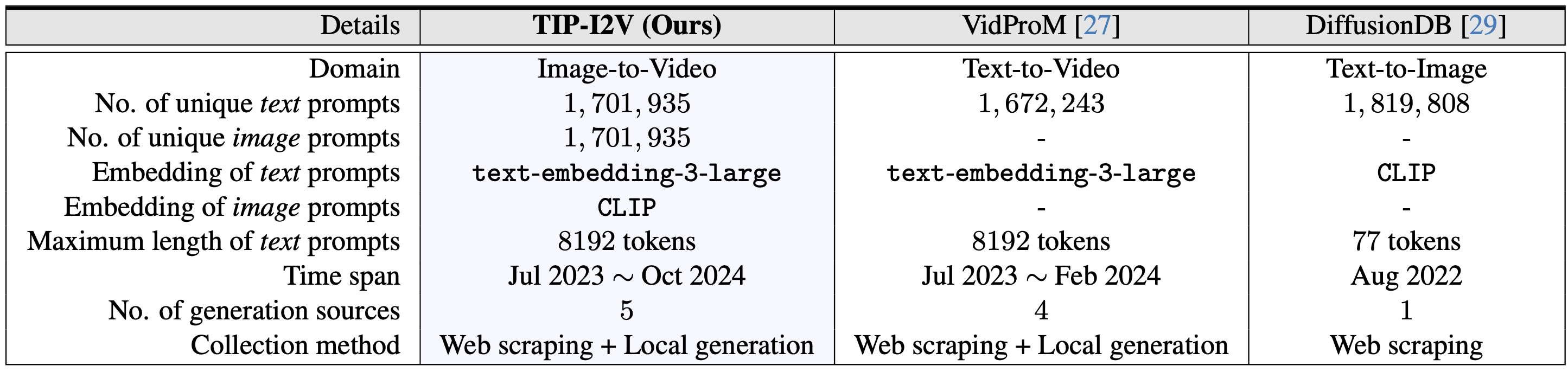
Comparison with VidProM and DiffusionDB
Paper

TIP-I2V: A Million-Scale Real Text and Image Prompt Dataset for Image-to-Video Generation
Wenhao Wang and Yi Yang
Arxiv, 2024.
@article{wang2024tip-i2v,
title={TIP-I2V: A Million-Scale Real Text and Image Prompt Dataset for Image-to-Video Generation},
author={Wang, Wenhao and Yang, Yi},
journal={arXiv preprint arXiv:2411.04709},
year={2024},
}Contact
If you have any questions, feel free to contact Wenhao Wang (wangwenhao0716@gmail.com).
Works based on TIP-I2V
We are actively collecting your awesome works based on our TIP-I2V. Please let us know if you finish one.
Acknowledgements
We sincerely thank OpenAI for their support through the Researcher Access Program. Without their generous contribution, this work would not have been possible.